
はじめまして、AMDlabの掛田です。
PythonとBeautiful Soupを使って、AMDlab Tech Blogの記事一覧ページに含まれる記事のタイトルと記事詳細ページURLをスクレイピングするプログラムを紹介します。
Beautiful SoupはHTMLから欲しい情報を抽出するライブラリです(Beautiful SoupがHTMLを取得するわけではない)。
今回は、RequestsライブラリでHTMLを取得してからBeautiful Soupで情報を抽出します。
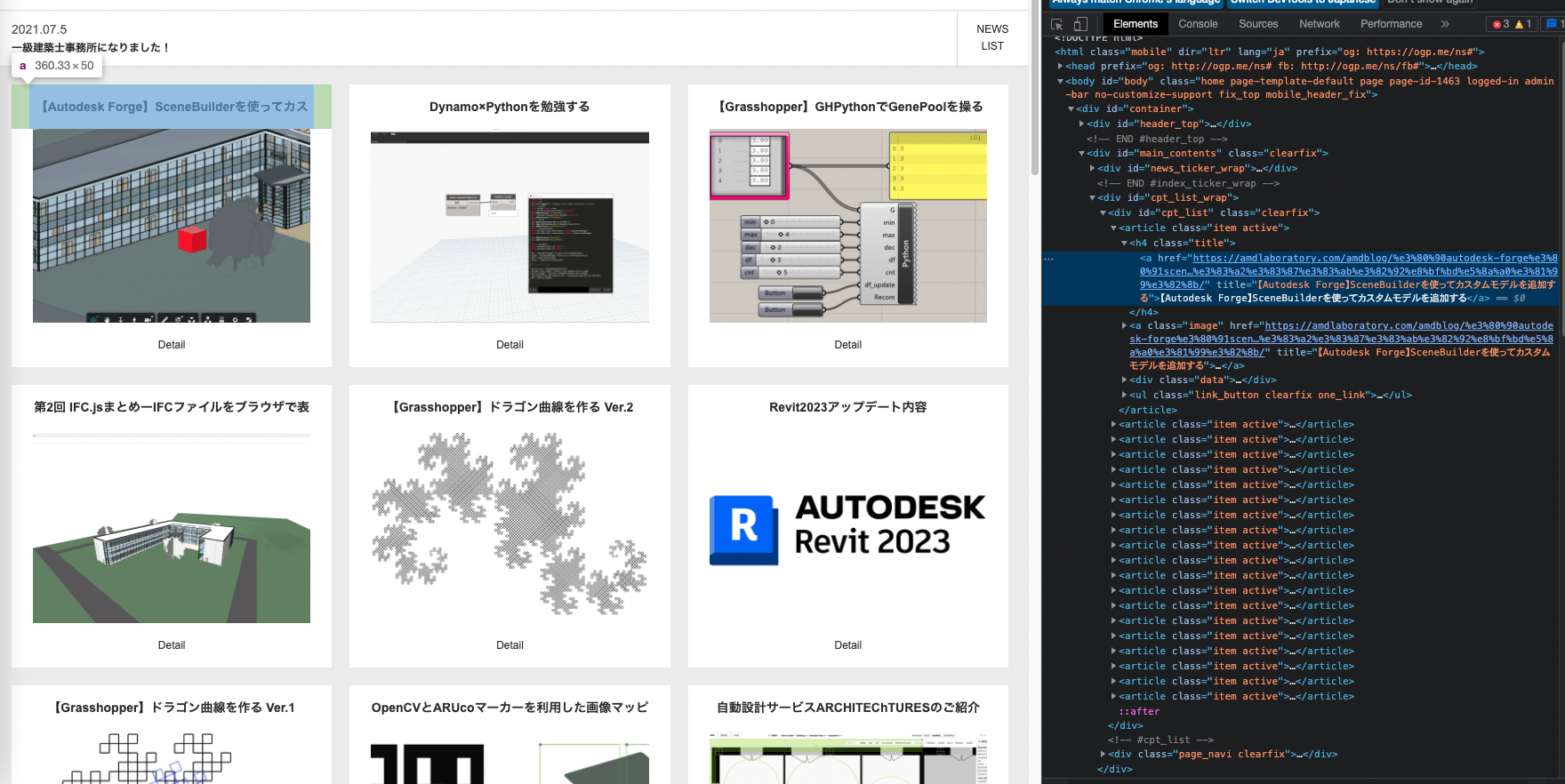
記事一覧ページの一覧部分はid=”cpt_list”を持つdivタグ内に複数のarticleタグが入っている構造になっていて、articleタグが1記事分の要素です。
今回欲しい情報はarticleタグ内の孫階層にあるaタグです。
aタグのhrefに各記事詳細ページURLとタグ内のテキストにタイトルがあるので、これらを抽出していきます。
バージョン
Python: 3.10.6
Beautiful Soup: 4.11.1
コード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
import time import requests from bs4 import BeautifulSoup # BeautifulSoupインスタンスを取得 def get_beautiful_soup(url): res = requests.get(url) return BeautifulSoup(res.content, "html.parser") # 1ページ分のタイトルとURL一覧を取得 def get_page_articles(soup): cpt_list = soup.find("div", {"id": "cpt_list"}) titles = cpt_list.find_all("h4", {"class": "title"}) page_articles = [] for title in titles: page_article = { "url": title.find("a").get("href"), "title": title.find("a").text } page_articles.append(page_article) return page_articles # ブログトップページのURL blog_top_page_url = "https://amdlaboratory.com/" top_page_soup = get_beautiful_soup(blog_top_page_url) # 最終的にはarticlesに全ての情報が入る articles = get_page_articles(top_page_soup) # 全ての記事一覧画面のURLがページネーションに入っているのでページネーションの要素を取得 page_numbers = top_page_soup.find_all("a", {"class": "page-numbers"}) # リストの最後の要素は次のページへ進む「>」要素なので除外しておく page_numbers.pop() # 2ページ目以降を全て処理 for page_number in page_numbers: # サイトに負荷をかけないようにリクエストを飛ばす間隔は1秒ごと time.sleep(1) link = page_number.get("href") page_soup = get_beautiful_soup(link) # 1ページ分のタイトルとURLをarticlesへ足していく articles.extend(get_page_articles(page_soup)) # スクレイピングの結果をターミナルへ出力 for article in articles: print(article["title"] + ":" + article["url"]) |
処理全体の流れを解説すると、
- Requestsでブログトップページ(1ページ目の記事一覧)のHTMLを取得
- 1で取得したHTMLから、1ページ目の記事一覧のタイトルと記事詳細ページURLの他に、2ページ目以降の記事一覧ページURLをページネーション要素から全て抽出しておく
- 2で取得した2ページ目以降の記事一覧ページURLをループにかけて、1ページずつ順にHTML取得と情報の抽出を繰り返す
- 最終的に全記事のタイトルと記事詳細ページURLの辞書を持つリストが出来上がるので、print()で出力して確認する
また、requests.get()を繰り返し使う場合は、
短い間隔でリクエストが飛んでしまってスクレイピング対象のサイトのサーバーに負荷が掛かってしまわないよう、time.sleep(秒数)で実行間隔をあけておきましょう。
今回はtime.sleep(1)で1秒あけてリクエストを飛ばしています。
実行結果
実行結果はこんな感じ↓ “タイトル: 記事詳細ページURL”の形式で出力できていることが確認できます。

スクレイピングに使えるライブラリは他にもあるので、皆さんもぜひ色々試してデータ収集に活用してみてください。


COMMENTS